
教程:Easy 搞定 Golang 设计模式 (yuque.com)
面向对象设计原则#
原则的目的: 高内聚,低耦合
单一职责原则#
类的职责单一,对外只提供一种功能,而引起类变化的原因都应该只有一个。
package main
import "fmt"
type ClothesShop struct {}
func (cs *ClothesShop) OnShop() {
fmt.Println("休闲的装扮")
}
type ClothesWork struct {}
func (cw *ClothesWork) OnWork() {
fmt.Println("工作的装扮")
}
func main() {
//工作的时候
cw := new(ClothesWork)
cw.OnWork()
//shopping的时候
cs := new(ClothesShop)
cs.OnShop()
}开闭原则#
开闭原则 (Open-Closed Principle, OCP)**: 类的改动是通过增加代码进行的,而不是修改源代码。
平铺式设计#
package main
import "fmt"
//我们要写一个类,Banker银行业务员
type Banker struct {
}
//存款业务
func (this *Banker) Save() {
fmt.Println( "进行了 存款业务...")
}
//转账业务
func (this *Banker) Transfer() {
fmt.Println( "进行了 转账业务...")
}
//支付业务
func (this *Banker) Pay() {
fmt.Println( "进行了 支付业务...")
}
func main() {
banker := &Banker{}
banker.Save()
banker.Transfer()
banker.Pay()
}这样设计我们看到功能是实现了,但是带来的维护问题也非常大.增加一个新的功能可能对原来稳定的代码造成影响,不利于后期维护.
开闭原则设计#
开闭原则: 一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
简单的说就是在修改需求的时候,应该尽量通过扩展来实现变化,而不是通过修改已有代码来实现变化
这里使用三个业务员实例分别实现接口,这样即使存款业务员的业务出问题了,不会影响到转账和支付.
package main
import "fmt"
//抽象的银行业务员
type AbstractBanker interface{
DoBusi() //抽象的处理业务接口
}
//存款的业务员
type SaveBanker struct {
//AbstractBanker
}
func (sb *SaveBanker) DoBusi() {
fmt.Println("进行了存款")
}
//转账的业务员
type TransferBanker struct {
//AbstractBanker
}
func (tb *TransferBanker) DoBusi() {
fmt.Println("进行了转账")
}
//支付的业务员
type PayBanker struct {
//AbstractBanker
}
func (pb *PayBanker) DoBusi() {
fmt.Println("进行了支付")
}
func main() {
//进行存款
sb := &SaveBanker{}
sb.DoBusi()
//进行转账
tb := &TransferBanker{}
tb.DoBusi()
//进行支付
pb := &PayBanker{}
pb.DoBusi()
}接口的意义#
实际上接口的最大的意义就是实现多态的思想,就是我们可以根据 interface 类型来设计 API 接口,那么这种 API 接口的适应能力不仅能适应当下所实现的全部模块,也适应未来实现的模块来进行调用。 调用未来 可能就是接口的最大意义所在吧,这也是为什么架构师那么值钱,因为良好的架构师是可以针对 interface 设计一套框架,在未来许多年却依然适用。
依赖倒转原则#
依赖倒转原则:模块与模块依赖抽象而不是具体实现
耦合度极高的模块关系设计#
package main
import "fmt"
// === > 奔驰汽车 <===
type Benz struct {
}
func (this *Benz) Run() {
fmt.Println("Benz is running...")
}
// === > 宝马汽车 <===
type BMW struct {
}
func (this *BMW) Run() {
fmt.Println("BMW is running ...")
}
//===> 司机张三 <===
type Zhang3 struct {
//...
}
func (zhang3 *Zhang3) DriveBenZ(benz *Benz) {
fmt.Println("zhang3 Drive Benz")
benz.Run()
}
func (zhang3 *Zhang3) DriveBMW(bmw *BMW) {
fmt.Println("zhang3 drive BMW")
bmw.Run()
}
//===> 司机李四 <===
type Li4 struct {
//...
}
func (li4 *Li4) DriveBenZ(benz *Benz) {
fmt.Println("li4 Drive Benz")
benz.Run()
}
func (li4 *Li4) DriveBMW(bmw *BMW) {
fmt.Println("li4 drive BMW")
bmw.Run()
}
func main() {
//业务1 张3开奔驰
benz := &Benz{}
zhang3 := &Zhang3{}
zhang3.DriveBenZ(benz)
//业务2 李四开宝马
bmw := &BMW{}
li4 := &Li4{}
li4.DriveBMW(bmw)
}这段代码没有使用 interface ,可以看到如果要来个 新司机,开一辆新车又要重写一遍 run ,Drive,这样大大增加了代码量,降低了后续维护的便利性.
面向抽象层依赖倒转#

如上图所示,如果我们在设计一个系统的时候,将模块分为 3 个层次,抽象层、实现层、业务逻辑层。那么,我们首先将抽象层的模块和接口定义出来,这里就需要了interface接口的设计,然后我们依照抽象层,依次实现每个实现层的模块,在我们写实现层代码的时候,实际上我们只需要参考对应的抽象层实现就好了,实现每个模块,也和其他的实现的模块没有关系,这样也符合了上面介绍的开闭原则。这样实现起来每个模块只依赖对象的接口,而和其他模块没关系,依赖关系单一。系统容易扩展和维护。
我们在指定业务逻辑也是一样,只需要参考抽象层的接口来业务就好了,抽象层暴露出来的接口就是我们业务层可以使用的方法,然后可以通过多态的线下,接口指针指向哪个实现模块,调用了就是具体的实现方法,这样我们业务逻辑层也是依赖抽象成编程。
我们就将这种的设计原则叫做依赖倒转原则。
package main
import "fmt"
// ===== > 抽象层 < ========
type Car interface {
Run()
}
type Driver interface {
Drive(car Car)
}
// ===== > 实现层 < ========
type BenZ struct {
//...
}
func (benz * BenZ) Run() {
fmt.Println("Benz is running...")
}
type Bmw struct {
//...
}
func (bmw * Bmw) Run() {
fmt.Println("Bmw is running...")
}
type Zhang_3 struct {
//...
}
func (zhang3 *Zhang_3) Drive(car Car) {
fmt.Println("Zhang3 drive car")
car.Run()
}
type Li_4 struct {
//...
}
func (li4 *Li_4) Drive(car Car) {
fmt.Println("li4 drive car")
car.Run()
}
// ===== > 业务逻辑层 < ========
func main() {
//张3 开 宝马
var bmw Car
bmw = &Bmw{}
var zhang3 Driver
zhang3 = &Zhang_3{}
zhang3.Drive(bmw)
//李4 开 奔驰
var benz Car
benz = &BenZ{}
var li4 Driver
li4 = &Li_4{}
li4.Drive(benz)
}合成复用原则#
合成复用原则:通过组合来实现父类方法
如果使用继承,会导致父类的任何变换都可能影响到子类的行为。如果使用对象组合,就降低了这种依赖关系。对于继承和组合,优先使用组合。
这里看到如果创建 worker 对象还需要初始化父类 Person ,而创建 teacher 对象则不需要.
package main
import "fmt"
// Person 父类
type Person struct {
Name string
Age int
}
func (p *Person) GetName() {
fmt.Println("Name: ", p.Name)
}
func (p *Person) New(name string, age int) {
p.Name = name
p.Age = age
}
// Worker 继承父类
type Worker struct {
Person
}
func (w *Worker) GetName() {
fmt.Println("Name: ", w.Name)
}
func (w *Worker) SetName(name string) {
w.Name = name
}
// Teacher 组合方式
type Teacher struct {
P *Person
Name string
}
func (t *Teacher) GetName() {
fmt.Println("Name: ", t.Name)
}
func (t *Teacher) SetName(name string) {
t.Name = name
}
func main() {
// 继承
w := Worker{Person{
Name: "jack",
Age: 10,
}}
w.GetName()
// 组合
t := Teacher{
P: nil,
Name: "mike",
}
t.GetName()
}输出结果:
Name: jack
Name: mike迪米特法则#
迪米特法则:依赖第三方来实现解耦
设计模式六大原则(五)—-迪米特法则 - 盛开的太阳 - 博客园 (cnblogs.com)
创造型模式#
简单工厂模式#
不使用工厂模式
依赖关系: 业务逻辑层 ---> 基础类模块
package main
import "fmt"
//水果类
type Fruit struct {
//...
//...
//...
}
func (f *Fruit) Show(name string) {
if name == "apple" {
fmt.Println("我是苹果")
} else if name == "banana" {
fmt.Println("我是香蕉")
} else if name == "pear" {
fmt.Println("我是梨")
}
}
//创建一个Fruit对象
func NewFruit(name string) *Fruit {
fruit := new(Fruit)
if name == "apple" {
//创建apple逻辑
} else if name == "banana" {
//创建banana逻辑
} else if name == "pear" {
//创建pear逻辑
}
return fruit
}
func main() {
apple := NewFruit("apple")
apple.Show("apple")
banana := NewFruit("banana")
banana.Show("banana")
pear := NewFruit("pear")
pear.Show("pear")
}不适用工厂模式带来的问题:
(1) 在 Fruit 类中包含很多if…else…代码块,整个类的代码相当冗长,代码越长,阅读难度、维护难度和测试难度也越大;而且大量条件语句的存在还将影响系统的性能,程序在执行过程中需要做大量的条件判断。
(2) Fruit 类的职责过重,它负责初始化和显示所有的水果对象,将各种水果对象的初始化代码和显示代码集中在一个类中实现,违反了“单一职责原则”,不利于类的重用和维护;
(3) 当需要增加新类型的水果时,必须修改 Fruit 类的构造函数 NewFruit() 和其他相关方法源代码,违反了“开闭原则”。
这样如果要增加新的Fruit种类就需要更改 Fruit类中的代码,耦合度高,不利于后期维护.这时候就需要个中间层(工厂模块层)将逻辑层也业务层隔离,实现解耦.
业务逻辑层 ---> 工厂模块 ---> 基础类模块
抽象层, 定义一个水果接口,具体类实现该接口.
// ======= 抽象层 =========
//水果类(抽象接口)
type Fruit interface {
Show() //接口的某方法
}实体类层,实现接口方法
// ====== 实体类层 =======
type Apple struct {
Fruit
}
func (apple *Apple) Show() {
fmt.Println("我是苹果")
}
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("我是香蕉")
}
type Orange struct {
Fruit
}
func (orange *Orange) Show() {
fmt.Println("我是橘子")
}工厂模块层 ,生产水果类,返回水果实体类指针.
// ====== 工厂模块 ======
type Factory struct {}
func (fac *Factory) CreateFruit(kind string) Fruit {
var fruit Fruit
if kind == "apple" {
fruit = new(Apple)
} else if kind == "banana" {
fruit = new(Banana)
} else if kind == "pear" {
fruit = new(Pear)
}
return fruit
}业务逻辑层,使用工厂模块生产水果实体类.
// ====== 业务逻辑层 ======
func main() {
factory := new(Factory)
apple := factory.CreateFruit("apple")
apple.Show()
banana := factory.CreateFruit("banana")
banana.Show()
pear := factory.CreateFruit("pear")
pear.Show()
}完整代码
/*
简单工厂模式
*/
// ======= 抽象层 =========
//水果类(抽象接口)
type Fruit interface {
Show() //接口的某方法
}
// ====== 实体类层 =======
type Apple struct {
Fruit
}
func (apple *Apple) Show() {
fmt.Println("我是苹果")
}
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("我是香蕉")
}
type Orange struct {
Fruit
}
func (orange *Orange) Show() {
fmt.Println("我是橘子")
}
// ====== 工厂模块 ======
type Factory struct {}
func (fac *Factory) CreateFruit(kind string) Fruit {
var fruit Fruit
if kind == "apple" {
fruit = new(Apple)
} else if kind == "banana" {
fruit = new(Banana)
} else if kind == "pear" {
fruit = new(Pear)
}
return fruit
}
// ====== 业务逻辑层 ======
func main() {
factory := new(Factory)
apple := factory.CreateFruit("apple")
apple.Show()
banana := factory.CreateFruit("banana")
banana.Show()
pear := factory.CreateFruit("pear")
pear.Show()
}简单工厂模式的优缺点:
优点:
- 实现了对象创建和使用的分离。
- 不需要记住具体类名,记住参数即可,减少使用者记忆量。
缺点:
- 对工厂类职责过重,一旦不能工作,系统受到影响。
- 增加系统中类的个数,复杂度和理解度增加。
- 违反“开闭原则”,添加新产品需要修改工厂逻辑,工厂越来越复杂。
适用场景:
- 工厂类负责创建的对象比较少,由于创建的对象较少,不会造成工厂方法中的业务逻辑太过复杂。
- 客户端只知道传入工厂类的参数,对于如何创建对象并不关心。
工厂方法模式#
工厂方法模式中的角色和职责: 抽象工厂(Abstract Factory)角色:工厂方法模式的核心,任何工厂类都必须实现这个接口。
工厂(Concrete Factory)角色:具体工厂类是抽象工厂的一个实现,负责实例化产品对象。
抽象产品(Abstract Product)角色:工厂方法模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
具体产品(Concrete Product)角色:工厂方法模式所创建的具体实例对象
简单工厂模式 + “开闭原则” = 工厂方法模式
为了避免简单工厂因为工厂类职责过重带来的问题,就由抽象层抽象出来水果类和工厂类来实现一个水果一个对应的工厂.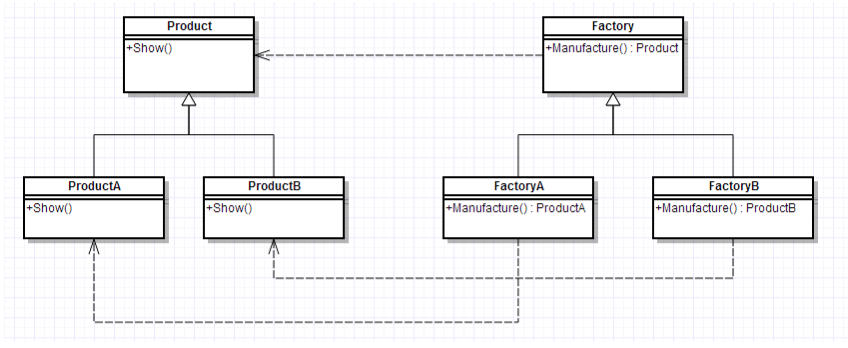
// ======= 抽象层 =========
// 水果接口
type Fruit interface {
Show() //接口的某方法
}
// 工厂接口
type AbstractFactory interface {
CreateFruit() Fruit // 生成水果的抽象方法
}实体类层
// ===== 实体类层 =====
// 苹果实体类
type Apple struct {
Fruit
}
func (apple *Apple) Show() {
fmt.Println("Apple")
}
// 香蕉实体类
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("Banana")
}工厂模块层
// ==== 工厂模块层 =====
// 苹果类对应的苹果工厂
type AppleFactory struct {
AbstractFactory
}
func (af *AppleFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = new(Apple)
return fruit
}
// 香蕉对应的工厂
type BananaFactory struct {
AbstractFactory
}
func (bf *BananaFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = new(Banana)
return fruit
}业务逻辑层
// ===== 业务实现层 =====
func main() {
// 创建苹果工厂生成苹果实例
var appleFactory AppleFactory
apple := appleFactory.CreateFruit()
apple.Show()
// 创建香蕉工厂生成香蕉实例
var bananaFactory BananaFactory
banana := bananaFactory.CreateFruit()
banana.Show()
}完整代码
/*
工厂方法模式
*/
package main
import "fmt"
// ======= 抽象层 =========
// 水果接口
type Fruit interface {
Show() //接口的某方法
}
// 工厂接口
type AbstractFactory interface {
CreateFruit() Fruit // 生成水果的抽象方法
}
// ===== 实体类层 =====
//
type Apple struct {
Fruit
}
func (apple *Apple) Show () {
fmt.Println("Apple")
}
type Banana struct {
Fruit
}
func (banana *Banana) Show() {
fmt.Println("Banana")
}
// ==== 工厂模块层 =====
type AppleFactory struct{
AbstractFactory
}
func (af *AppleFactory) CreateFruit() Fruit{
var fruit Fruit
fruit = new(Apple)
return fruit
}
type BananaFactory struct{
AbstractFactory
}
func (bf *BananaFactory) CreateFruit() Fruit{
var fruit Fruit
fruit = new(Banana)
return fruit
}
// ===== 业务实现层 =====
func main() {
// 创建苹果工厂生成苹果实例
var appleFactory AppleFactory
apple := appleFactory.CreateFruit()
apple.Show()
// 创建香蕉工厂生成香蕉实例
var bananaFactory BananaFactory
banana := bananaFactory.CreateFruit()
banana.Show()
}工厂方法模式的优缺点:
优点:
- 不需要记住具体类名,甚至连具体参数都不用记忆。
- 实现了对象创建和使用的分离。
- 系统的可扩展性也就变得非常好,无需修改接口和原类。
- 对于新产品的创建,符合开闭原则。
缺点:
- 增加系统中类的个数,复杂度和理解度增加。
- 增加了系统的抽象性和理解难度。
适用场景:
- 客户端不知道它所需要的对象的类。
- 抽象工厂类通过其子类来指定创建哪个对象
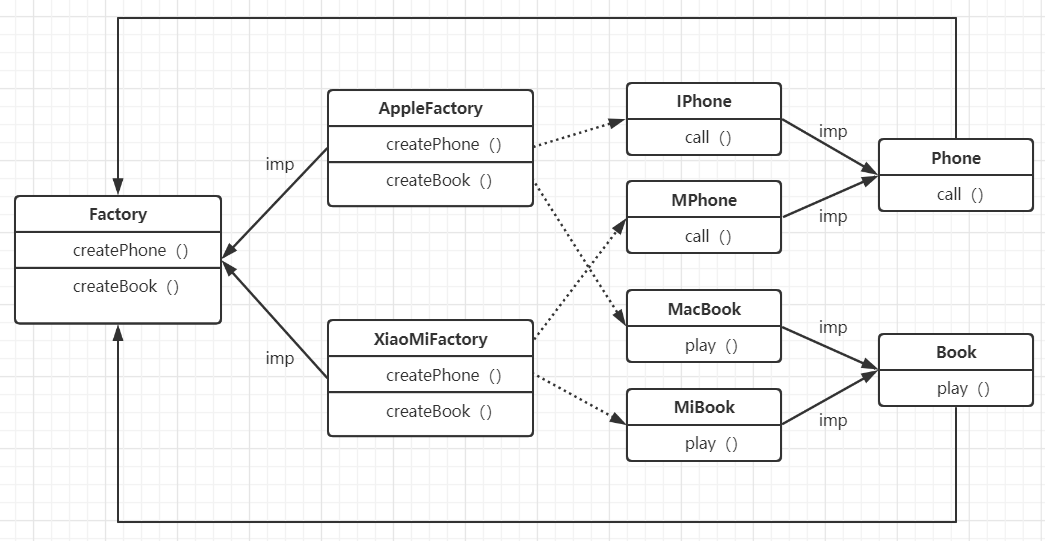
抽象工厂方法模式#
工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。
因此,可以考虑将一些相关的产品组成一个“产品族”,由同一个工厂来统一生产.这就是抽象工厂方法模式.
- 抽象工厂模式可以将简单工厂模式和工厂方法模式进行整合。
- 从设计层面看,抽象工厂模式就是对简单工厂模式的改进(或者称为进一步的抽象)。
- 将工厂抽象成两层,抽象工厂 和 具体实现的工厂子类。程序员可以根据创建对象类型使用对应的工厂子类。这样将单个的简单工厂类变成了工厂集合, 更利于代码的维护和扩展。
———————————————— 版权声明:本文为CSDN博主「Mitsuha三葉」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_42804736/article/details/115168313
产品族和产品等级结构#
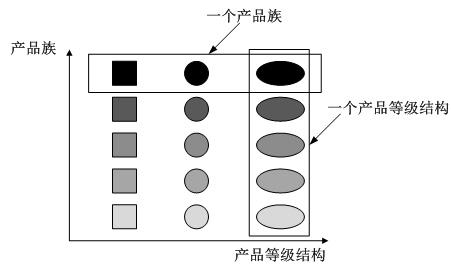
上图表示“产品族”和“产品登记结构”的关系。 产品族:具有同一个地区、同一个厂商、同一个开发包、同一个组织模块等,但是具备不同特点或功能的产品集合,称之为是一个产品族。
产品等级结构:具有相同特点或功能,但是来自不同的地区、不同的厂商、不同的开发包、不同的组织模块等的产品集合,称之为是一个产品等级结构。
当程序中的对象可以被划分为产品族和产品等级结构之后,那么“抽象工厂方法模式”才可以被适用。
“抽象工厂方法模式”是针对“产品族”进行生产产品.
抽象工厂方法模式实现#
抽象层
/*
抽象工厂方法
*/
// ======= 抽象层 =========
// AbstractApple 接口
type AbstractApple interface {
ShowApple()
}
// AbstractBanana 接口
type AbstractBanana interface {
ShowBanana()
}
// Factory 接口
type Factory interface {
CreateApple() AbstractApple
CreateBanana() AbstractBanana
}实现层
// ===== 实现类层 =====
// 中国产品族
type ChinaApple struct {
AbstractApple
}
// 实现 AbstractApple 接口
func (ca *ChinaApple) ShowApple() {
fmt.Println("ChinaApple")
}
type ChinaBanana struct {
AbstractBanana
}
// 实现 AbstractBanana 接口
func (cb *ChinaBanana) ShowBanana() {
fmt.Println("ChinaBanana")
}
type ChinaFactory struct {
Factory
}
// 实现 Factory 接口
func (cf *ChinaFactory) CreateApple() AbstractApple {
var chinaApple ChinaApple
return &chinaApple
}
// 实现 Factory 接口
func (cf *ChinaFactory) CreateBanana() AbstractBanana {
var chinabanana ChinaBanana
return &chinabanana
}
// 日本产品族
type JapanApple struct {
AbstractApple
}
func (ja *JapanApple) ShowApple() {
fmt.Println("JapanApple")
}
type JapanBanana struct {
AbstractBanana
}
func (jb *JapanBanana) ShowBanana() {
fmt.Println("JapanBanana")
}
type JapanFactory struct {
Factory
}
func (jf *JapanFactory) CreateApple() AbstractApple {
var japanApple JapanApple
return &japanApple
}
func (jf *JapanFactory) CreateBanana() AbstractBanana {
var japanBanana JapanBanana
return &japanBanana
}业务层
func main() {
// 中国工厂
var cf ChinaFactory
ca := cf.CreateApple()
cb := cf.CreateBanana()
ca.ShowApple()
cb.ShowBanana()
// 日本工厂
var jf JapanFactory
ja := jf.CreateApple()
jb := jf.CreateBanana()
ja.ShowApple()
jb.ShowBanana()
}完整代码
package main
import "fmt"
// ======= 抽象层 =========
// AbstractApple 接口
type AbstractApple interface {
ShowApple()
}
// AbstractBanana 接口
type AbstractBanana interface {
ShowBanana()
}
// Factory 接口
type Factory interface {
CreateApple() AbstractApple
CreateBanana() AbstractBanana
}
// ===== 实现类层 =====
// 中国产品族
type ChinaApple struct {
AbstractApple
}
// 实现 AbstractApple 接口
func (ca *ChinaApple) ShowApple() {
fmt.Println("ChinaApple")
}
type ChinaBanana struct {
AbstractBanana
}
// 实现 AbstractBanana 接口
func (cb *ChinaBanana) ShowBanana() {
fmt.Println("ChinaBanana")
}
type ChinaFactory struct {
Factory
}
// 实现 Factory 接口
func (cf *ChinaFactory) CreateApple() AbstractApple {
var chinaApple ChinaApple
return &chinaApple
}
// 实现 Factory 接口
func (cf *ChinaFactory) CreateBanana() AbstractBanana {
var chinabanana ChinaBanana
return &chinabanana
}
// 日本产品族
type JapanApple struct {
AbstractApple
}
func (ja *JapanApple) ShowApple() {
fmt.Println("JapanApple")
}
type JapanBanana struct {
AbstractBanana
}
func (jb *JapanBanana) ShowBanana() {
fmt.Println("JapanBanana")
}
type JapanFactory struct {
Factory
}
func (jf *JapanFactory) CreateApple() AbstractApple {
var japanApple JapanApple
return &japanApple
}
func (jf *JapanFactory) CreateBanana() AbstractBanana {
var japanBanana JapanBanana
return &japanBanana
}
func main() {
// 中国工厂
var cf ChinaFactory
ca := cf.CreateApple()
cb := cf.CreateBanana()
ca.ShowApple()
cb.ShowBanana()
// 日本工厂
var jf JapanFactory
ja := jf.CreateApple()
jb := jf.CreateBanana()
ja.ShowApple()
jb.ShowBanana()
}输出结果:
ChinaApple
ChinaBanana
JapanApple
JapanBanana优点:
- 拥有工厂方法模式的优点
- 当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象。
3 增加新的产品族很方便,无须修改已有系统,符合“开闭原则”。
缺点:
- 增加新的产品等级结构麻烦,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这显然会带来较大的不便,违背了“开闭原则”。
教程里面的练习:
练习: 设计一个电脑主板架构,电脑包括(显卡,内存,CPU)3个固定的插口,显卡具有显示功能(display,功能实现只要打印出意义即可),内存具有存储功能(storage),cpu具有计算功能(calculate)。 现有Intel厂商,nvidia厂商,Kingston厂商,均会生产以上三种硬件。 要求组装两台电脑, 1台(Intel的CPU,Intel的显卡,Intel的内存) 1台(Intel的CPU, nvidia的显卡,Kingston的内存) 用抽象工厂模式实现。
//我的代码
package main
import (
"fmt"
)
/******* 抽象层 ********/
type AbstractCPU interface {
calculate()
}
type AbstractVedioCard interface {
display()
}
type AbstractRAM interface {
storage()
}
type Factory interface {
CreateCPU() AbstractCPU
CreateRAM() AbstractRAM
CreateVedioCard() AbstractVedioCard
}
type AbstractComputer interface {
SetCPU(AbstractCPU)
SetRAM(AbstractRAM)
SetVedioCard(AbstractVedioCard)
}
/******* 实体类层 ********/
// INTEL
type IntelFactory struct {
Factory
}
func (ifac *IntelFactory) CreateCPU() AbstractCPU {
var ic IntelCPU
return &ic
}
func (ifac *IntelFactory) CreateRAM() AbstractRAM {
var ir IntelRAM
return &ir
}
func (ifac *IntelFactory) CreateVedioCard() AbstractVedioCard {
var ivc IntelVedioCard
return &ivc
}
type IntelCPU struct {
AbstractCPU
}
func (ic *IntelCPU) calculate() {
fmt.Println("IntelCPU_Calculate")
}
type IntelVedioCard struct {
AbstractVedioCard
}
func (ivc *IntelVedioCard) display() {
fmt.Println("IntelVedioCard_Display")
}
type IntelRAM struct {
AbstractRAM
}
func (ir *IntelRAM) storage() {
fmt.Println("IntelRAM_Storage")
}
// NVIDIA族 Factory
type NvidiaFactory struct {
Factory
}
func (nfac *NvidiaFactory) CreateCPU() AbstractCPU {
var nc NvidiaCPU
return &nc
}
func (nfac *NvidiaFactory) CreateRAM() AbstractRAM {
var nr NvidiaRAM
return &nr
}
func (nfac *NvidiaFactory) CreateVedioCard() AbstractVedioCard {
var nvc NvidiaVedioCard
return &nvc
}
type NvidiaCPU struct {
AbstractCPU
}
func (nc *NvidiaCPU) calculate() {
fmt.Println("NvidiaCPU_Calculate")
}
type NvidiaVedioCard struct {
AbstractVedioCard
}
func (nvc *NvidiaVedioCard) display() {
fmt.Println("NvidiaVedioCard_Display")
}
type NvidiaRAM struct {
AbstractRAM
}
func (nr *NvidiaRAM) storage() {
fmt.Println("NvidiaRAM_Storage")
}
// NVIDIA族 Factory
type KingstonFactory struct {
Factory
}
func (nfac *KingstonFactory) CreateCPU() AbstractCPU {
var kc KingstonCPU
return &kc
}
func (nfac *KingstonFactory) CreateRAM() AbstractRAM {
var kr KingstonRAM
return &kr
}
func (nfac *KingstonFactory) CreateVedioCard() AbstractVedioCard {
var kvc KingstonVedioCard
return &kvc
}
type KingstonCPU struct {
AbstractCPU
}
func (kc *KingstonCPU) calculate() {
fmt.Println("KingstonCPU_Calculate")
}
type KingstonVedioCard struct {
AbstractVedioCard
}
func (kvc *KingstonVedioCard) display() {
fmt.Println("KingstonVedioCard_Display")
}
type KingstonRAM struct {
AbstractRAM
}
func (kr *KingstonRAM) storage() {
fmt.Println("KingstonRAM_Storage")
}
// Computer
type Computer struct {
CPU AbstractCPU
RAM AbstractRAM
VedioCard AbstractVedioCard
}
func (c *Computer) SetCPU(CPU AbstractCPU) {
c.CPU = CPU
}
func (c *Computer) SetRAM(RAM AbstractRAM) {
c.RAM = RAM
}
func (c *Computer) SetVedioCard(VedioCard AbstractVedioCard) {
c.VedioCard = VedioCard
}
/******* 业务实现层 ********/
func main() {
// 工厂
var ifac IntelFactory
var nfac NvidiaFactory
var kfac KingstonFactory
ic := ifac.CreateCPU()
ir := ifac.CreateRAM()
ivc := ifac.CreateVedioCard()
nvc := nfac.CreateVedioCard()
kr := kfac.CreateRAM()
var c1 Computer
c1.SetCPU(ic)
c1.SetRAM(ir)
c1.SetVedioCard(ivc)
c1.CPU.calculate()
c1.RAM.storage()
c1.VedioCard.display()
var c2 Computer
c2.SetCPU(ic)
c2.SetRAM(kr)
c2.SetVedioCard(nvc)
c2.CPU.calculate()
c2.RAM.storage()
c2.VedioCard.display()
}运行结果:
IntelCPU_Calculate
IntelRAM_Storage
IntelVedioCard_Display
IntelCPU_Calculate
KingstonRAM_Storage
NvidiaVedioCard_Display单例模式#
Singleton(单例):在单例类的内部实现只生成一个实例,同时它提供一个静态的getInstance()工厂方法,让客户可以访问它的唯一实例;为了防止在外部对其实例化,将其构造函数设计为私有;在单例类内部定义了一个Singleton类型的静态对象,作为外部共享的唯一实例。

单例模式要解决的问题是:
保证一个类永远只能有一个对象,且该对象的功能依然能被其他模块使用。
单例模式(饿汉模式)
package main
import "fmt"
/*
三个要点:
一是某个类只能有一个实例;
二是它必须自行创建这个实例;
三是它必须自行向整个系统提供这个实例。
*/
/*
保证一个类永远只能有一个对象
*/
//1、保证这个类非公有化,外界不能通过这个类直接创建一个对象
// 那么这个类就应该变得非公有访问 类名称首字母要小写
type singelton struct {}
//2、但是还要有一个指针可以指向这个唯一对象,但是这个指针永远不能改变方向
// Golang中没有常指针概念,所以只能通过将这个指针私有化不让外部模块访问
var instance *singelton = new(singelton)
//3、如果全部为私有化,那么外部模块将永远无法访问到这个类和对象,
// 所以需要对外提供一个方法来获取这个唯一实例对象
// 注意:这个方法是否可以定义为singelton的一个成员方法呢?
// 答案是不能,因为如果为成员方法就必须要先访问对象、再访问函数
// 但是类和对象目前都已经私有化,外界无法访问,所以这个方法一定是一个全局普通函数
func GetInstance() *singelton {
return instance
}
func (s *singelton) SomeThing() {
fmt.Println("单例对象的某方法")
}
func main() {
s := GetInstance()
s.SomeThing()
}饿汉模式:
在初始化单例唯一指针的时候,就已经提前开辟好了一个对象,申请了内存.
饿汉式的好处是,不会出现线程并发创建,导致多个单例的出现,但是缺点是如果这个单例对象在业务逻辑没有被使用,也会客观的创建一块内存对象。那么与之对应的模式叫“懒汉式”
单例模式 (懒汉模式)
package main
import "fmt"
type singelton struct {
}
var instance *singelton = new(singelton)
func GetInstance() *singelton {
// 如果对选哪个为空,创建一个新对象,否则不创建
if instance == nil {
instance = new(singelton)
return instance
}
return instance
}
func (i *singelton) Print() {
fmt.Println("Hello")
}
func main(){
si := GetInstance()
si.Print()
}懒汉模式虽然解决了饿汉模式的问题,但是也带来一个问题,就是如果有多个协程同时首次调用GetInstance()方法有概率导致多个实例被创建,则违背了单例的设计初衷。 由此我们可以进行加读写锁的操作来防止被创建多个实例.
package main
import (
"fmt"
"sync"
)
type singelton struct {
}
var lock sync.Mutex
var instance *singelton = new(singelton)
func GetInstance() *singelton {
// 调用 GetInstance() 的时候加锁,防止别的协程使用
lock.Lock()
defer lock.Unlock()
// 如果对选哪个为空,创建一个新对象,否则不创建
if instance == nil {
return new(singelton)
}
return instance
}
func (i *singelton) print() {
fmt.Println("Hello")
}
func main(){
si := GetInstance()
si.print()
}但是加上读写锁带来的问题就是,如果并发数量高了,会导致很多调用GetInstance()的协程被 一个读写锁阻塞,从而拖慢速度.
线程安全的单例模式#
所以接下来可以借助"sync/atomic"来进行内存的状态存留来做互斥。atomic就可以自动加载和设置标记.
// sync/atomic"来进行内存的状态存留来做互斥
package main
import (
"fmt"
"sync"
"sync/atomic"
)
type singelton struct {
}
var initialized uint32
var lock sync.Mutex
var instance *singelton = new(singelton)
func GetInstance() *singelton {
//如果标记为被设置,直接返回,不加锁
if atomic.LoadUint32(&initialized) == 1 {
return instance
}
lock.Lock()
defer lock.Unlock()
// 标记为0 创建一个新的,同时将标记设置为1.表示已经有实例
if initialized == 0{
instance = new(singelton)
//设置标记位
atomic.StoreUint32(&initialized, 1)
}
return instance
}
func (i *singelton) print() {
fmt.Println("Hello")
}
func main(){
si := GetInstance()
si.print()
}当然也可以使用 sync 包中的 Once.Do() 方法来实现上面的操作
package main
import (
"fmt"
"sync"
)
type singelton struct {
}
var once sync.Once
var instance *singelton = new(singelton)
func GetInstance() *singelton {
once.Do(func () {
instance = new(singelton)
})
return instance
}
func (i *singelton) print() {
fmt.Println("Hello")
}
func main(){
si := GetInstance()
si.print()
}sync.Once.Do 源码:
func (o *Once) Do(f func()) {
// Note: Here is an incorrect implementation of Do:
//
// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {
// f()
// }
//
// Do guarantees that when it returns, f has finished.
// This implementation would not implement that guarantee:
// given two simultaneous calls, the winner of the cas would
// call f, and the second would return immediately, without
// waiting for the first's call to f to complete.
// This is why the slow path falls back to a mutex, and why
// the atomic.StoreUint32 must be delayed until after f returns.
if atomic.LoadUint32(&o.done) == 0 {
// Outlined slow-path to allow inlining of the fast-path.
o.doSlow(f)
}
}优点:
(1) 单例模式提供了对唯一实例的受控访问。
(2) 节约系统资源。由于在系统内存中只存在一个对象。
缺点:
(1) 扩展略难。单例模式中没有抽象层。 (2) 单例类的职责过重。
结构性模式#
代理模式#
Proxy模式又叫做代理模式,是构造型的设计模式之一,它可以为其他对象提供一种代理(Proxy)以控制对这个对象的访问。
所谓代理,是指具有与代理元(被代理的对象)具有相同的接口的类,客户端必须通过代理与被代理的目标类交互,而代理一般在交互的过程中(交互前后),进行某些特别的处理。
用一个日常可见的案例来理解“代理”的概念,如下图: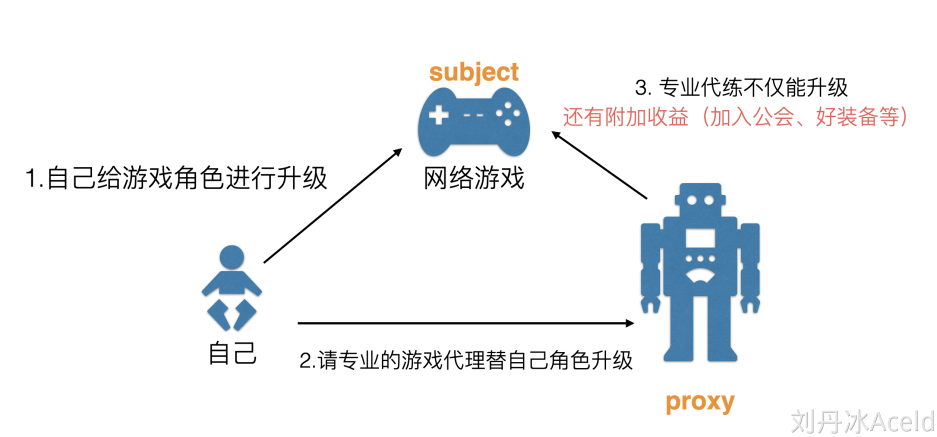
(1)“自己”有一个给游戏角色升级的需求或者任务,当然“自己”可以独自完成游戏任务的升级。
(2)或者“自己”也可以邀请以为更加擅长游戏的“游戏代练”来完成升级这件事,这个代练就是“Proxy”代理。
(3)“游戏代练”不仅能够完成升级的任务需求,还可以额外做一些附加的能力。比如打到一些好的游戏装备、加入公会等等周边收益。
所以代理的出现实则是为了能够覆盖“自己”的原本的需求,且可以额外做其他功能,这种额外创建的类是不影响已有的“自己”和“网络游戏”的的关系。是额外添加,在设计模式原则上,是符合“开闭原则”思想。
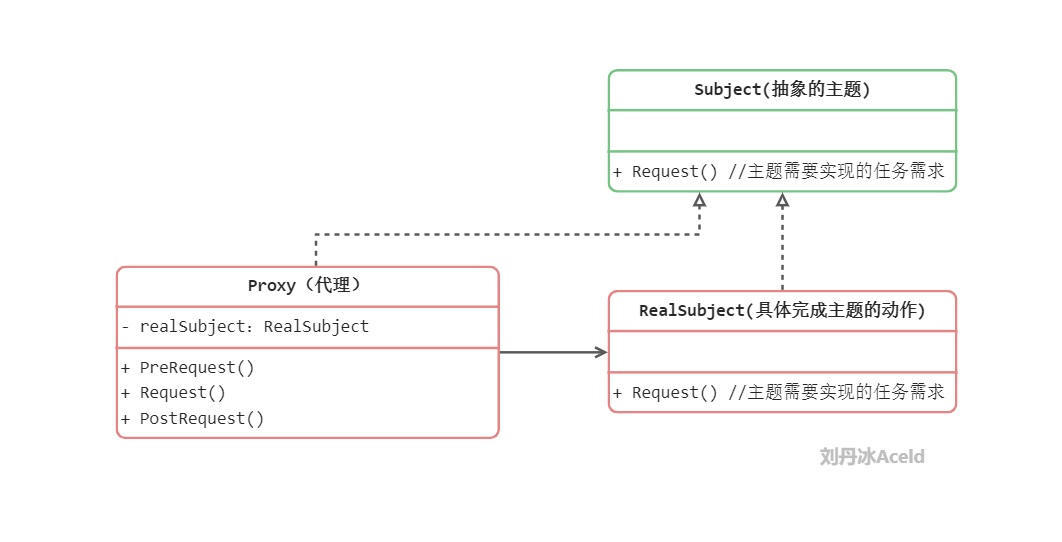
subject(抽象主题角色):真实主题与代理主题的共同接口。
RealSubject(真实主题角色):定义了代理角色所代表的真实对象。
Proxy(代理主题角色): 含有对真实主题角色的引用,代理角色通常在将客户端调用传递给真是主题对象之前或者之后执行某些操作,而不是单纯返回真实的对象。 实例
/*
代理模式
*/
package main
import (
"fmt"
)
// 角色
type Character struct {
ID string // 角色ID
Level int // 等级
Banned bool // 是否被
}
// Player 抽象层
type Player interface {
UpLevel(character *Character)
}
// ChinaPlayer 实现层
type ChinaPlayer struct {
Player
}
func (cp *ChinaPlayer) UpLevel(character *Character) {
fmt.Println("ChinaPlayer将", character.ID, "的角色等级提升了100级")
character.Level = 100
fmt.Println("现在角色等级为: ", character.Level)
}
type USPlayer struct {
Player
}
func (up *USPlayer) UpLevel(character *Character) {
fmt.Println("US Player将", character.ID, "的角色等级提升了100级")
character.Level = 100
fmt.Println("现在角色等级为: ", character.Level)
}
// Booster 代理
type Booster struct {
player Player // 代理某个主题
}
func (bsr *Booster) UpLevel(character *Character) {
// 先查看是否被封
if bsr.checkBanned(character) == false {
bsr.player.UpLevel(character) // 调用原来的函数
bsr.Done(character)
}
}
func MakeBooster(player Player) Player {
return &Booster{player}
}
func (bsr *Booster) checkBanned(character *Character) bool {
fmt.Println("Scan ", character.ID)
if character.Banned {
fmt.Println(character.ID, "is Banned")
}
return character.Banned
}
func (bsr *Booster) Done(character *Character) {
fmt.Println("Booster将", character.ID, "的角色等级提升了100级")
character.Level = 100
fmt.Println("现在角色等级为: ", character.Level)
}
func main() {
ch1 := Character{
ID: "11",
Level: 10,
Banned: false,
}
ch2 := Character{
ID: "22",
Level: 0,
Banned: false,
}
ch3 := Character{
ID: "33",
Level: 0,
Banned: true,
}
ch4 := Character{
ID: "44",
Level: 0,
Banned: false,
}
// 不使用代理
var player Player
player = new(ChinaPlayer)
player.UpLevel(&ch1)
player = new(ChinaPlayer)
player.UpLevel(&ch2)
// 使用代理模式
var boostPlayer Player
boostPlayer = MakeBooster(player)
boostPlayer.UpLevel(&ch3)
boostPlayer.UpLevel(&ch4)
}输出结果
ChinaPlayer将 11 的角色等级提升了100级
现在角色等级为: 100
ChinaPlayer将 22 的角色等级提升了100级
现在角色等级为: 100
Scan 33
33 is Banned
Scan 44
ChinaPlayer将 44 的角色等级提升了100级
现在角色等级为: 100
Booster将 44 的角色等级提升了100级
现在角色等级为: 100代理模式的优缺点
优点: (1) 能够协调调用者和被调用者,在一定程度上降低了系统的耦合度。 (2) 客户端可以针对抽象主题角色进行编程,增加和更换代理类无须修改源代码,符合开闭原则,系统具有较好的灵活性和可扩展性。
缺点: (1) 代理实现较为复杂。
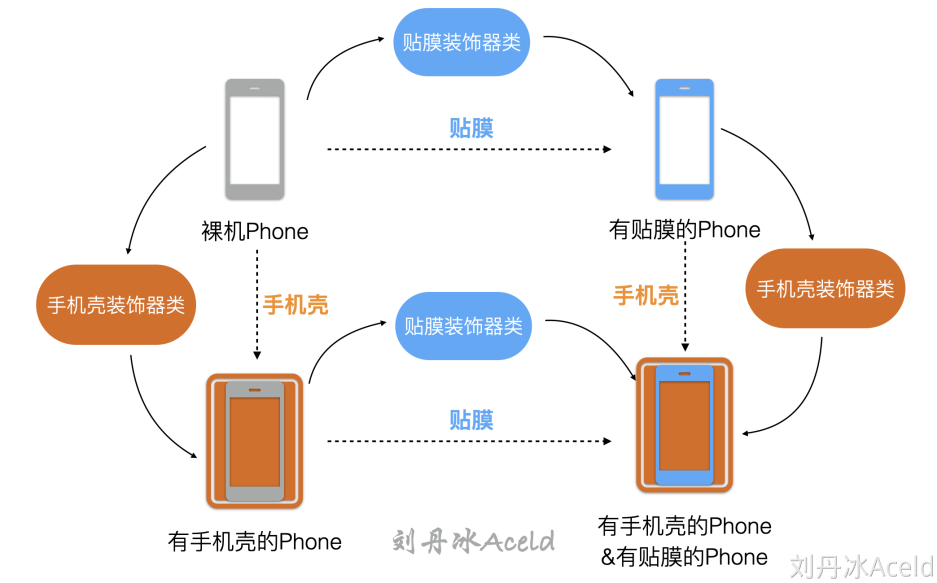
装饰模式#
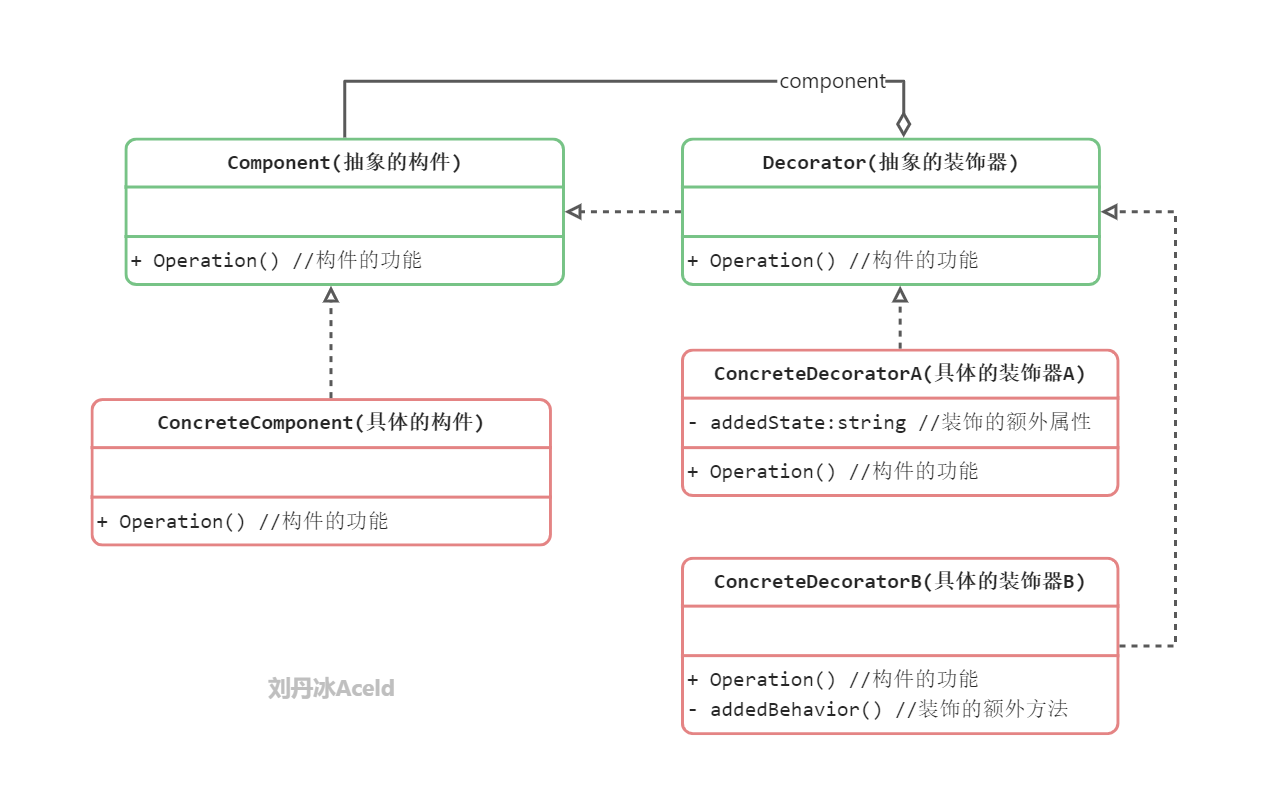
装饰模式(Decorator Pattern):动态地给一个对象增加一些额外的职责,就增加对象功能来说,装饰模式比生成子类实现更为灵活。装饰模式是一种对象结构型模式。
Component(抽象构件):它是具体构件和抽象装饰类的共同父类,声明了在具体构件中实现的业务方法,它的引入可以使客户端以一致的方式处理未被装饰的对象以及装饰之后的对象,实现客户端的透明操作。
ConcreteComponent(具体构件):它是抽象构件类的子类,用于定义具体的构件对象,实现了在抽象构件中声明的方法,装饰器可以给它增加额外的职责(方法)。
和代理模式的区别在于 装饰器模式可以自由组合,而代理模式有内部逻辑无法自由组合
package main
import "fmt"
//--- 抽象层 ----
// Phone 手机抽象层
type Phone interface{
Show()
}
// 抽象装饰器 基础类
//(该类本应该为interface,但是Golang interface语法不可以有成员属性)
type Decorator struct{
phone Phone
}
func (d *Decorator) Show(){
}
// ---- 实体类层 ----
type Huawei struct{
}
func (h *Huawei) Show(){
fmt.Println("Huawei Phone")
}
type Xiaomi struct{
}
func (x *Xiaomi) Show(){
fmt.Println("Xiaomi Phone")
}
type MoDecorator struct {
Decorator // 继承Decorator 主要方法
}
func (x *MoDecorator) Show(){
x.phone.Show()
fmt.Println("Phone Mo")
}
func NewMoDecorator(phone Phone) Phone{
return &MoDecorator{Decorator{phone}}
}
func main(){
hw := new(Huawei)
hw.Show()
xm := new(Xiaomi)
xm.Show()
md := NewMoDecorator(hw)
md.Show()
}输出结果:
Huawei Phone
Xiaomi Phone
Huawei Phone
Phone Mo优点:
(1) 对于扩展一个对象的功能,装饰模式比继承更加灵活性,不会导致类的个数急剧增加。
(2) 可以通过一种动态的方式来扩展一个对象的功能,从而实现不同的行为。
(3) 可以对一个对象进行多次装饰。
(4) 具体构件类与具体装饰类可以独立变化,用户可以根据需要增加新的具体构件类和具体装饰类,原有类库代码无须改变,符合“开闭原则”。
缺点:
(1) 使用装饰模式进行系统设计时将产生很多小对象,大量小对象的产生势必会占用更多的系统资源,影响程序的性能。
(2) 装饰模式提供了一种比继承更加灵活机动的解决方案,但同时也意味着比继承更加易于出错,排错也很困难,对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为繁琐。
适配器模式#
适配器模式(Adapter Pattern) : 将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
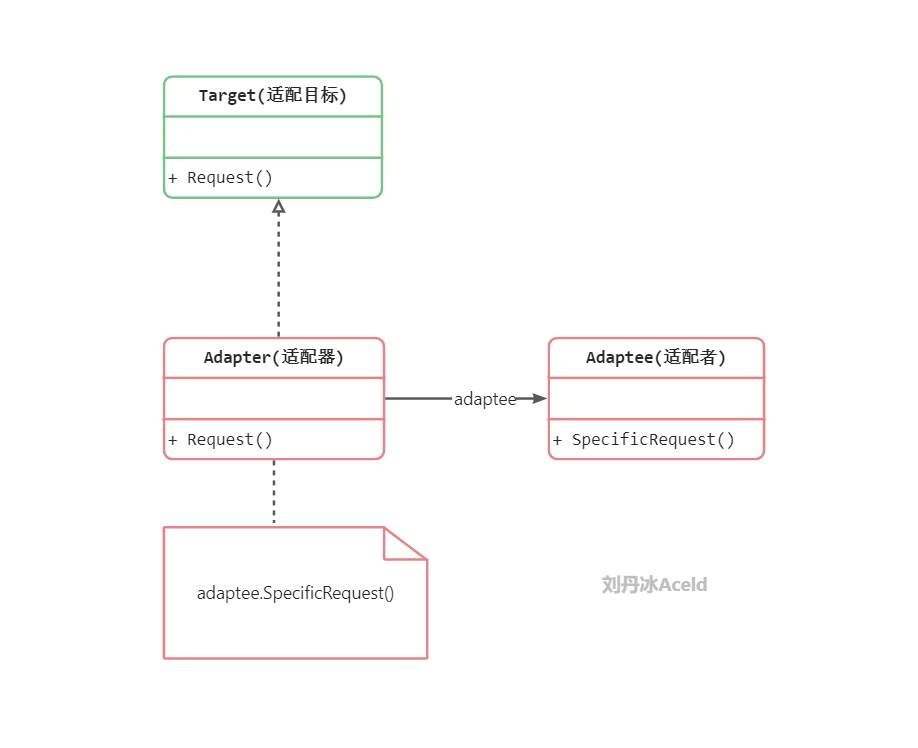
package main
import "fmt"
//适配的目标
type V5 interface {
Use5V()
}
//业务类,依赖V5接口
type Phone struct {
v V5
}
func NewPhone(v V5) *Phone {
return &Phone{v}
}
func (p *Phone) Charge() {
fmt.Println("Phone进行充电...")
p.v.Use5V()
}
//被适配的角色,适配者
type V220 struct {}
func (v *V220) Use220V() {
fmt.Println("使用220V的电压")
}
//电源适配器
type Adapter struct {
v220 *V220
}
func (a *Adapter) Use5V() {
fmt.Println("使用适配器进行充电")
//调用适配者的方法
a.v220.Use220V()
}
func NewAdapter(v220 *V220) *Adapter {
return &Adapter{v220}
}
// ------- 业务逻辑层 -------
func main() {
iphone := NewPhone(NewAdapter(new(V220)))
iphone.Charge()
}输出结果:
Phone进行充电...
使用适配器进行充电
使用220V的电压其他实例
package main
import "fmt"
// 攻击接口
type Attack interface{
Fight()
}
// 英雄类
type Hero struct {
Name string
Attack Attack
}
func NewHero(name string,attack Attack) *Hero{
return &Hero{name,attack}
}
func (h *Hero) Do(){
fmt.Println(h.Name,"Attack...")
h.Attack.Fight()
}
// 关机类
type PowerOff struct{
}
func (po *PowerOff) ShutDown(){
fmt.Println("Commputer ShutDown....")
}
type Adapter struct{
powerOff *PowerOff
}
func (ap *Adapter) Fight(){
ap.powerOff.ShutDown()
}
func NewAdapter(powerOff *PowerOff) *Adapter{
return &Adapter{powerOff}
}
func main(){
hero := NewHero("12313",NewAdapter(new(PowerOff)))
hero.Do()
}优点:
(1) 将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无须修改原有结构。
(2) 增加了类的透明性和复用性,将具体的业务实现过程封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一个适配者类可以在多个不同的系统中复用。
(3) 灵活性和扩展性都非常好,可以很方便地更换适配器,也可以在不修改原有代码的基础上增加新的适配器类,完全符合“开闭原则”。
缺点:
适配器中置换适配者类的某些方法比较麻烦。
外观模式#
根据迪米特法则,如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。
Facade模式也叫外观模式,是由GoF提出的23种设计模式中的一种。Facade模式为一组具有类似功能的类群,比如类库,子系统等等,提供一个一致的简单的界面。这个一致的简单的界面被称作facade。
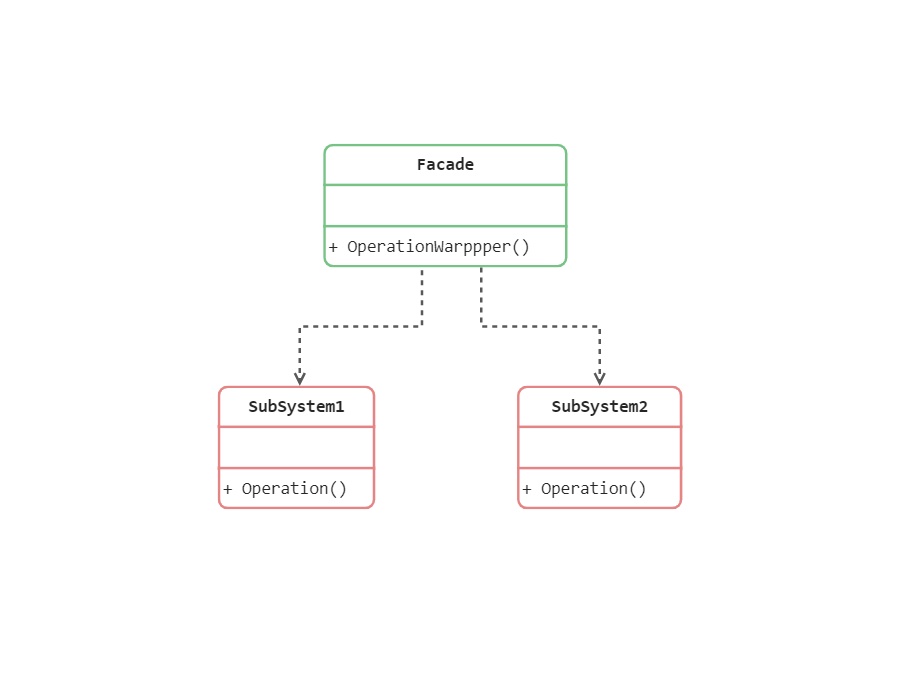
package main
import "fmt"
type SubSystemA struct {}
func (sa *SubSystemA) MethodA() {
fmt.Println("子系统方法A")
}
type SubSystemB struct {}
func (sb *SubSystemB) MethodB() {
fmt.Println("子系统方法B")
}
type SubSystemC struct {}
func (sc *SubSystemC) MethodC() {
fmt.Println("子系统方法C")
}
type SubSystemD struct {}
func (sd *SubSystemD) MethodD() {
fmt.Println("子系统方法D")
}
//外观模式,提供了一个外观类, 简化成一个简单的接口供使用
type Facade struct {
a *SubSystemA
b *SubSystemB
c *SubSystemC
d *SubSystemD
}
func (f *Facade) MethodOne() {
f.a.MethodA()
f.b.MethodB()
}
func (f *Facade) MethodTwo() {
f.c.MethodC()
f.d.MethodD()
}
func main() {
//如果不用外观模式实现MethodA() 和 MethodB()
sa := new(SubSystemA)
sa.MethodA()
sb := new(SubSystemB)
sb.MethodB()
fmt.Println("-----------")
//使用外观模式
f := Facade{
a: new(SubSystemA),
b: new(SubSystemB),
c: new(SubSystemC),
d: new(SubSystemD),
}
//调用外观包裹方法
f.MethodOne()
}子系统方法A
子系统方法B
-----------
子系统方法A
子系统方法B优点:
(1) 它对客户端屏蔽了子系统组件,减少了客户端所需处理的对象数目,并使得子系统使用起来更加容易。通过引入外观模式,客户端代码将变得很简单,与之关联的对象也很少。
(2) 它实现了子系统与客户端之间的松耦合关系,这使得子系统的变化不会影响到调用它的客户端,只需要调整外观类即可。
(3) 一个子系统的修改对其他子系统没有任何影响。
缺点:
(1) 不能很好地限制客户端直接使用子系统类,如果对客户端访问子系统类做太多的限制则减少了可变性和灵活 性。
(2) 如果设计不当,增加新的子系统可能需要修改外观类的源代码,违背了开闭原则。
行为型模式#
模板方法模式#
模板方法模式 在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。
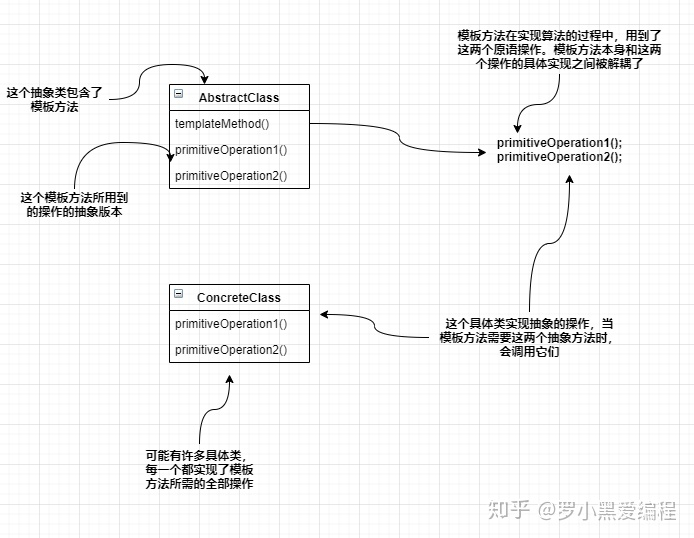
AbstractClass(抽象类): 在抽象类中定义了一系列基本操作(PrimitiveOperations),这些基本操作可以是具体的,也可以是抽象的,每一个基本操作对应算法的一个步骤,在其子类中可以重定义或实现这些步骤。同时,在抽象类中实现了一个模板方法(Template Method),用于定义一个算法的框架,模板方法不仅可以调用在抽象类中实现的基本方法,也可以调用在抽象类的子类中实现的基本方法,还可以调用其他对象中的方法。
ConcreteClass(具体子类) 它是抽象类的子类,用于实现在父类中声明的抽象基本操作以完成子类特定算法的步骤,也可以覆盖在父类中已经实现的具体基本操作。
抽象层
type Beverage interface {
BoilWater()
Brew()
PourInCup()
AddThings()
}
// 封装一套流程末班基类,让具体集成且实现
type Template struct {
b Beverage
}
func (t *Template) MakeBeverage() {
if t == nil {
return
}
t.b.BoilWater()
t.b.Brew()
t.b.PourInCup()
t.b.AddThings()
}实体类层
// MakeCoffee集成模板
type MakeCoffee struct {
Template
}
func (mc *MakeCoffee) BoilWater() {
fmt.Println("将水烧到 100 度")
}
func (mc *MakeCoffee) Brew() {
fmt.Println("冲泡")
}
func (mc *MakeCoffee) PourInCup() {
fmt.Println("导入杯中")
}
func (mc *MakeCoffee) AddThings() {
fmt.Println("添加牛奶")
}
func NewMakeCoffee() *MakeCoffee{
makeCoffee := new(MakeCoffee)
makeCoffee.b = makeCoffee
return makeCoffee
}
// MakeTea集成模板
type MakeTea struct{
Template
}
func (mt *MakeTea) BoilWater() {
fmt.Println("将水烧到 100 度")
}
func (mt *MakeTea) Brew() {
fmt.Println("冲泡茶叶")
}
func (mt *MakeTea) PourInCup() {
fmt.Println("导入杯中")
}
func (mt *MakeTea) AddThings() {
fmt.Println("添加枸杞")
}
func NewMakeTea() *MakeTea{
makeTea := new(MakeTea)
makeTea.b = makeTea
return makeTea
}业务层
func main() {
makeCoffee := NewMakeCoffee()
makeCoffee.MakeBeverage()
makeTea := NewMakeTea()
makeTea.MakeBeverage()
}完整代码
package main
import "fmt"
type Beverage interface {
BoilWater()
Brew()
PourInCup()
AddThings()
}
// 封装一套流程末班基类,让具体集成且实现
type Template struct {
b Beverage
}
func (t *Template) MakeBeverage() {
if t == nil {
return
}
t.b.BoilWater()
t.b.Brew()
t.b.PourInCup()
t.b.AddThings()
}
// MakeCoffee集成模板
type MakeCoffee struct {
Template
}
func (mc *MakeCoffee) BoilWater() {
fmt.Println("将水烧到 100 度")
}
func (mc *MakeCoffee) Brew() {
fmt.Println("冲泡")
}
func (mc *MakeCoffee) PourInCup() {
fmt.Println("导入杯中")
}
func (mc *MakeCoffee) AddThings() {
fmt.Println("添加牛奶")
}
func NewMakeCoffee() *MakeCoffee{
makeCoffee := new(MakeCoffee)
makeCoffee.b = makeCoffee
return makeCoffee
}
// MakeTea集成模板
type MakeTea struct{
Template
}
func (mt *MakeTea) BoilWater() {
fmt.Println("将水烧到 100 度")
}
func (mt *MakeTea) Brew() {
fmt.Println("冲泡茶叶")
}
func (mt *MakeTea) PourInCup() {
fmt.Println("导入杯中")
}
func (mt *MakeTea) AddThings() {
fmt.Println("添加枸杞")
}
func NewMakeTea() *MakeTea{
makeTea := new(MakeTea)
makeTea.b = makeTea
return makeTea
}
func main() {
makeCoffee := NewMakeCoffee()
makeCoffee.MakeBeverage()
makeTea := NewMakeTea()
makeTea.MakeBeverage()
}输出结果:
将水烧到 100 度
冲泡
导入杯中
添加牛奶
将水烧到 100 度
冲泡茶叶
导入杯中
添加枸杞优点:
(1) 在父类中形式化地定义一个算法,而由它的子类来实现细节的处理,在子类实现详细的处理算法时并不会改变算法中步骤的执行次序。
(2) 模板方法模式是一种代码复用技术,它在类库设计中尤为重要,它提取了类库中的公共行为,将公共行为放在父类中,而通过其子类来实现不同的行为,它鼓励我们恰当使用继承来实现代码复用。
(3) 可实现一种反向控制结构,通过子类覆盖父类的钩子方法来决定某一特定步骤是否需要执行。
(4) 在模板方法模式中可以通过子类来覆盖父类的基本方法,不同的子类可以提供基本方法的不同实现,更换和增加新的子类很方便,符合单一职责原则和开闭原则。
缺点:
需要为每一个基本方法的不同实现提供一个子类,如果父类中可变的基本方法太多,将会导致类的个数增加,系统更加庞大,设计也更加抽象。
命令模式#
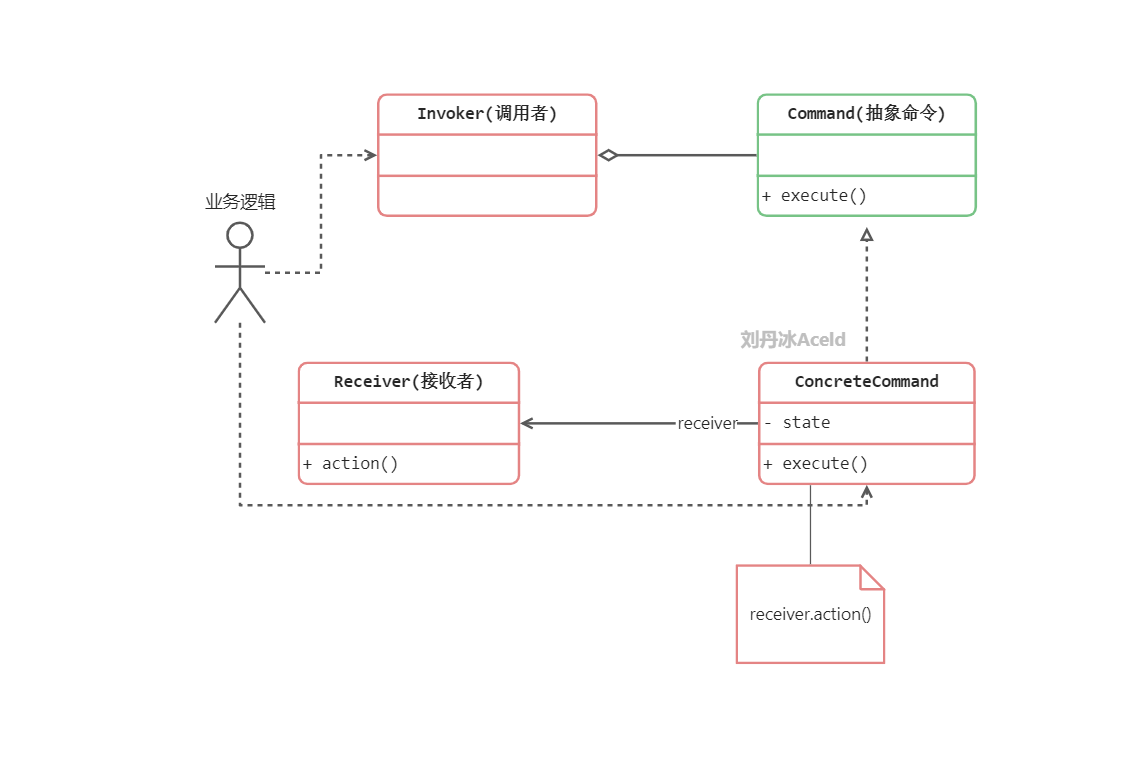
Command(抽象命令类): 抽象命令类一般是一个抽象类或接口,在其中声明了用于执行请求的execute()等方法,通过这些方法可以调用请求接收者的相关操作。
ConcreteCommand(具体命令类): 具体命令类是抽象命令类的子类,实现了在抽象命令类中声明的方法,它对应具体的接收者对象,将接收者对象的动作绑定其中。在实现execute()方法时,将调用接收者对象的相关操作(Action)。
Invoker(调用者): 调用者即请求发送者,它通过命令对象来执行请求。一个调用者并不需要在设计时确定其接收者,因此它只与抽象命令类之间存在关联关系。在程序运行时可以将一个具体命令对象注入其中,再调用具体命令对象的execute()方法,从而实现间接调用请求接收者的相关操作。
Receiver(接收者): 接收者执行与请求相关的操作,它具体实现对请求的业务处理。
package main
import "fmt"
// Receiver 接收者
type Receiver struct {
}
// Command 抽象的命令
type Command interface {
execute()
}
//
func (r *Receiver) action() {
fmt.Println("Command action")
}
// ConcreteCommand
type ConcreteCommand struct {
receiver *Receiver
}
func (cc *ConcreteCommand) execute() {
fmt.Println("ConcreteCommand execute")
cc.receiver.action()
}
// Invoker 调度着
type Invoker struct {
CmdList []Command
}
func (i *Invoker) Notify() {
fmt.Println("Invoker Notify")
if i.CmdList == nil {
return
}
for _, cmd := range i.CmdList {
cmd.execute()
}
}
func main() {
r := new(Receiver)
i := new(Invoker)
cmd := ConcreteCommand{r}
i.CmdList = append(i.CmdList,&cmd)
i.Notify()
}输出结果:
Invoker Notify
ConcreteCommand Execute
Command Action优点:
(1) 降低系统的耦合度。由于请求者与接收者之间不存在直接引用,因此请求者与接收者之间实现完全解耦,相同的请求者可以对应不同的接收者,同样,相同的接收者也可以供不同的请求者使用,两者之间具有良好的独立性。
(2) 新的命令可以很容易地加入到系统中。由于增加新的具体命令类不会影响到其他类,因此增加新的具体命令类很容易,无须修改原有系统源代码,甚至客户类代码,满足“开闭原则”的要求。
(3) 可以比较容易地设计一个命令队列或宏命令(组合命令)。
缺点:
使用命令模式可能会导致某些系统有过多的具体命令类。因为针对每一个对请求接收者的调用操作都需要设计一个具体命令类,因此在某些系统中可能需要提供大量的具体命令类,这将影响命令模式的使用。
策略模式#
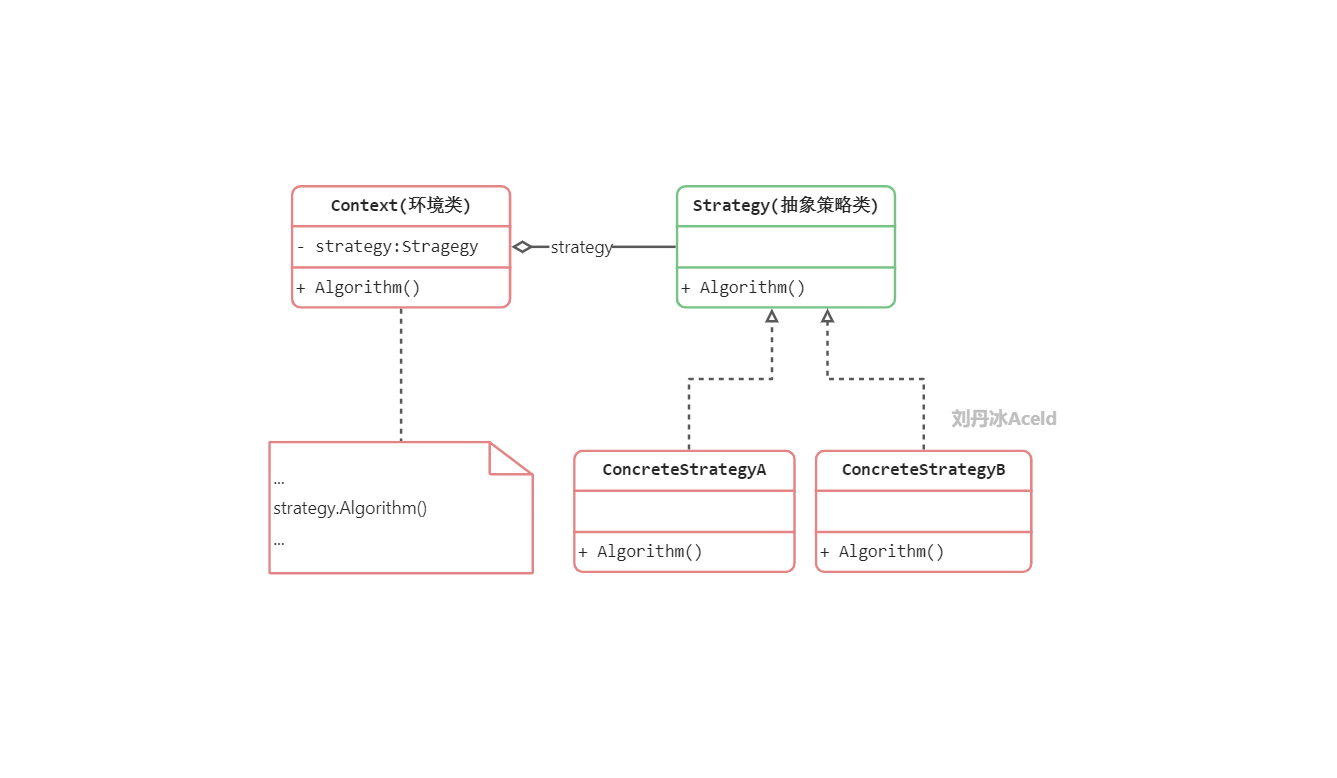
Context(环境类):环境类是使用算法的角色,它在解决某个问题(即实现某个方法)时可以采用多种策略。在环境类中维持一个对抽象策略类的引用实例,用于定义所采用的策略。
Strategy(抽象策略类):它为所支持的算法声明了抽象方法,是所有策略类的父类,它可以是抽象类或具体类,也可以是接口。环境类通过抽象策略类中声明的方法在运行时调用具体策略类中实现的算法。
ConcreteStrategy(具体策略类):它实现了在抽象策略类中声明的算法,在运行时,具体策略类将覆盖在环境类中定义的抽象策略类对象,使用一种具体的算法实现某个业务处理。
package main
import "fmt"
// 武器抽象策略
type WeaponStrategy interface {
UseWeapon()
}
// 具体实现层
// 具体策略AK47
type AK47 struct{}
func (ak *AK47) UseWeapon() {
fmt.Println("Use AK47")
}
type Knife struct{}
func (kf *Knife) UseWeapon() {
fmt.Println("Use Knife")
}
// Person 使用策略
type Person struct {
Strategy WeaponStrategy
}
func (p *Person) SetWeaponStrategy(s WeaponStrategy) {
p.Strategy = s
}
func (p *Person) Fight() {
p.Strategy.UseWeapon()
}
// 业务层
func main() {
p := new(Person)
p.SetWeaponStrategy(new(AK47))
p.Fight()
p.SetWeaponStrategy(new(Knife))
p.Fight()
}输出结果:
Use AK47
Use Knife优点:
(1) 策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
(2) 使用策略模式可以避免多重条件选择语句。多重条件选择语句不易维护,它把采取哪一种算法或行为的逻辑与算法或行为本身的实现逻辑混合在一起,将它们全部硬编码(Hard Coding)在一个庞大的多重条件选择语句中,比直接继承环境类的办法还要原始和落后。
(3) 策略模式提供了一种算法的复用机制。由于将算法单独提取出来封装在策略类中,因此不同的环境类可以方便地复用这些策略类。
缺点:
(1) 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法。换言之,策略模式只适用于客户端知道所有的算法或行为的情况。
(2) 策略模式将造成系统产生很多具体策略类,任何细小的变化都将导致系统要增加一个新的具体策略类。
观察者模式#
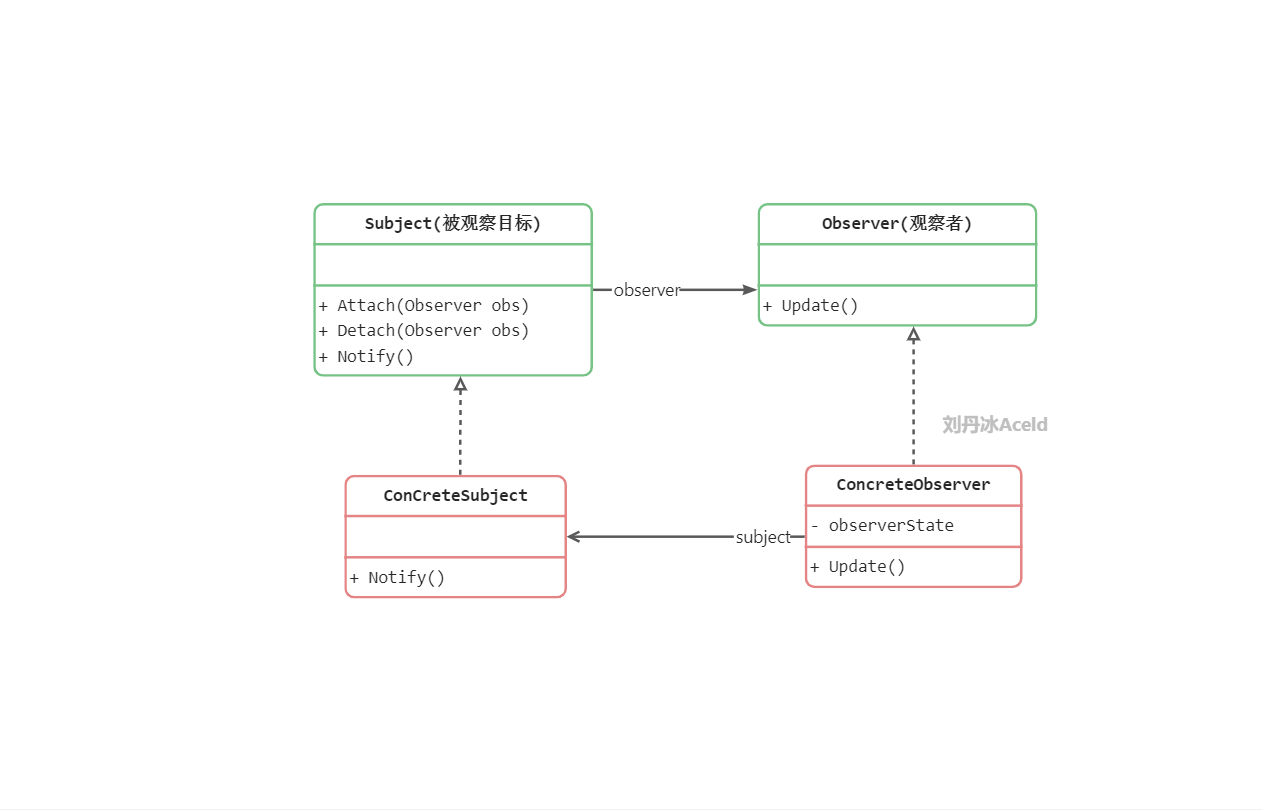
Subject(被观察者或目标,抽象主题): 被观察的对象。当需要被观察的状态发生变化时,需要通知队列中所有观察者对象。Subject需要维持(添加,删除,通知)一个观察者对象的队列列表。
ConcreteSubject(具体被观察者或目标,具体主题): 被观察者的具体实现。包含一些基本的属性状态及其他操作。
Observer(观察者): 接口或抽象类。当Subject的状态发生变化时,Observer对象将通过一个callback函数得到通知。
ConcreteObserver(具体观察者): 观察者的具体实现。得到通知后将完成一些具体的业务逻辑处理。
package main
import "fmt"
// ======= 抽象层 =======
// Listener 抽象观察者
type Listener interface {
Listen()
}
type Notifier interface {
AddListener(listener Listener)
RemoveListener(listener Listener)
Notify()
}
// ======= 实现层 ========
// Listener01 观察者01
type Listener01 struct {
Name string
Action string
}
func (l1 *Listener01) DoAction() {
fmt.Println(l1.Name, "Do Action")
}
func (l1 *Listener01) Listen() {
fmt.Println(l1.Name, "Stop Do", l1.Action)
}
// Listener02 观察者02
type Listener02 struct {
Name string
Action string
}
func (l2 *Listener02) DoAction() {
fmt.Println(l2.Name, "Do Action")
}
func (l2 *Listener02) Listen() {
fmt.Println(l2.Name, "Stop Do", l2.Action)
}
// Notifier01 通知者
type Notifier01 struct {
ListenerList []Listener // 观察者的数组
}
func (n1 *Notifier01) AddListener(listener Listener) {
n1.ListenerList = append(n1.ListenerList, listener)
}
func (n1 *Notifier01) RemoveListener(listener Listener) {
for index, listen := range n1.ListenerList {
// 找到要删除listener 的位置
if listener == listen {
//将要删除的元素前后位置连起来
n1.ListenerList = append(n1.ListenerList[:index], n1.ListenerList[index+1:]...)
break
}
}
}
func (n1 *Notifier01) Notify() {
for _, listen := range n1.ListenerList {
// 调用每个 listener listen.Listen()
}
}
func main() {
l1 := &Listener01{"L1", "Action"}
l2 := &Listener02{"L2", "Action"}
n1 := new(Notifier01)
n1.AddListener(l1)
n1.AddListener(l2)
l1.DoAction()
l2.DoAction()
n1.Notify()
n1.RemoveListener(l2)
n1.RemoveListener(l1)
}输出结果:
L1 Do Action
L2 Do Action
L1 Stop Do Action
L2 Stop Do Action优点:
(1) 观察者模式可以实现表示层和数据逻辑层的分离,定义了稳定的消息更新传递机制,并抽象了更新接口,使得可以有各种各样不同的表示层充当具体观察者角色。
(2) 观察者模式在观察目标和观察者之间建立一个抽象的耦合。观察目标只需要维持一个抽象观察者的集合,无须了解其具体观察者。由于观察目标和观察者没有紧密地耦合在一起,因此它们可以属于不同的抽象化层次。
(3) 观察者模式支持广播通信,观察目标会向所有已注册的观察者对象发送通知,简化了一对多系统设计的难度。
(4) 观察者模式满足“开闭原则”的要求,增加新的具体观察者无须修改原有系统代码,在具体观察者与观察目标之间不存在关联关系的情况下,增加新的观察目标也很方便。
缺点:
(1) 如果一个观察目标对象有很多直接和间接观察者,将所有的观察者都通知到会花费很多时间。
(2) 如果在观察者和观察目标之间存在循环依赖,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
(3) 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。